MDM Maturity model and quantitative measurements
One of the important factors that contribute to the organizational acceptance and long term sustainability of any large scale, multi year program is the ability measure the progress. Unfortunately master data management does not have many accepted measures. Many organizations try to use organizational KPIs and try to link MDM initiatives to them. This could prove to be a hard exercise since there are many layers between technology initiatives and their outputs and business results.
The initial step should be to establish a set of measures acceptable to both the IT people and Business community. There are measurements needed on both IT side and Business side. A clear understanding and agreement of them and balance of them is essential for the for the long term sustainability of MDM program.
1.1 Identification and definition of business data entities
One of the most important steps in creating a roadmap and a measurable multi year MDM program is the identification of business data entities in the master data domain. These constitute the ‘Scope’ portion of what we are measuring. And then we move on to the measures, which constitute the ‘What’ portion.
On a high level, this could be a simple beginning. Like Say Customer, Product/Asset, Location/Store/Site, Physician etc. And there are not a lot of master data entities in any organization, let us say a couple to a dozen depending on how granular you go. And it is relatively easy to have a starting point definition. But that is not enough for any practical purposes.
Let us take an example of customer. A common perception is, customer is somebody who pays the organization eventually. But let us focus on the airline industry, there are lot of intermediaries between the airline company and the end traveller. So if the airline is creating a customer data hub, is it the travellers who ultimately uses the airline? Or is it the intermediary who buys the tickets in bulk from the airline and then resell? Common agreement could be that the customer is the traveller. But if you want to focus on revenues in the next year or so, another MDM domain to focus could be the vendors or say re-sellers. But if you focus on that, immediately comes the question of how do we understand the vendors without knowing what kind of customers they are selling it.
In the telecom wireless industry many consider the customer as the individual who uses the mobile phone. But then what about the small business ‘Joes Pizza’ who purchased 10 units for its employees. Do we care about those employees who carry the phone and use it but does not pay directly for the service? Which line of business of the organization really own this segment of the customers? These issues should be addresses in the identification and definition of the “Business data entities”. And later constitute a mandatory pre-requisite and critical starting point in the scoping and road mapping exercises.
However, Identification of the business entities should be independent of these program scoping considerations. Where we consider this prioritization is in the roadmap creation. However the focus should be given to the master data entities. In other words transactional and analytical information should be filtered out as much as we can. Refer to the ‘MDM Layers’ section for more details on this. Scoping details are later in the ‘Business Measures’ and ‘Roadmap’ sections.
Ironically, a logical place to start this could very well be the IT department, specifically any common group which is neutral in it’s approach to any line of business or information systems. These guys have the advantage of being a common factor across variety of departments and document and escalate issues again for a common good of the enterprise.
Now, we started the earlier paragraph with the ‘logical place to start’ statement. So they can only start. Now, the business side has to take over when prioritizing, verifying the definitions etc.. Let us get back to this in the data governance sections.
1.2 Measures
An important criteria for selection and definition of these measures is the independence of these measures. That means these could be measured and improved almost independent of each other. Also these measures could be applied to specific business entities at a holistic level or it could be applied to a very specific finer grain data element or type of data. The tools and processes are used and skills required to improve each of the measures is relatively independent and could be applied at different timeframes.
These allow organizations to prioritize these measures in an independent fashion and apply resources in the areas important to them.
1.2.1 Technology Measures
These are intended to measure the technological maturity of the master data content and the fundamental organizational components for managing it over the years. This need not be tied to the master data management program. A master data management program is not even necessary to use these measures. But to focus our efforts and dollars on ‘data’ and not on all the tools and technologies and all the layers that comes on top of data, these measures will help. After all, master data management is about the management of ‘data’ of the type ‘master’.
These measures enable to adopt master data management and maturity of it as a series of smaller, focused project/investments rather than needing huge initiatives focusing on everything. The independence of measures help this objective.
Also a careful definition of these measures are selected so that these measures are independent of each other. This is different from many industry standard definitions which overlaps each other and thus results in confusion.
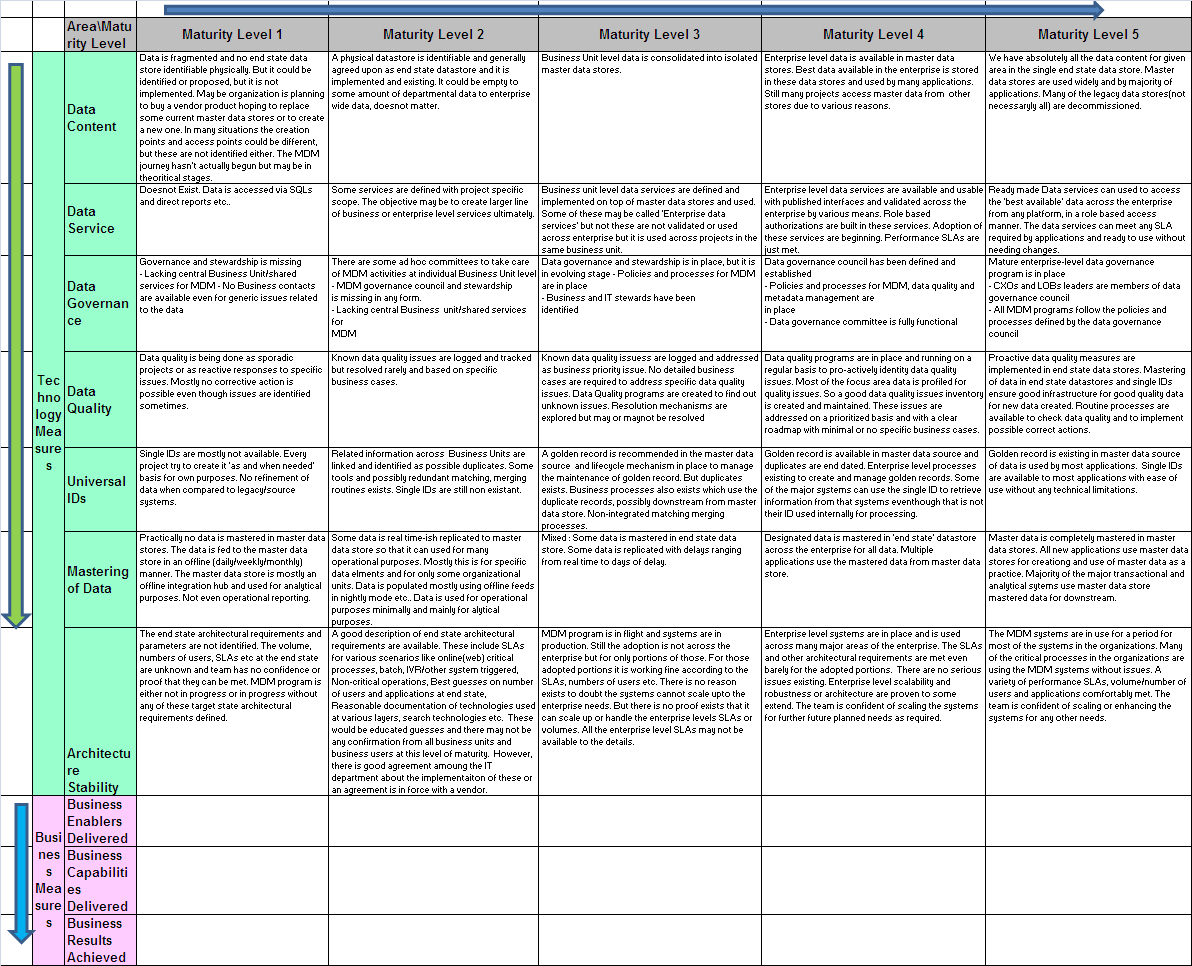
1) Data Content: This measures the organizational breadth and depth of master data the organization wanting to address versus what it is addressing at any given moment. The breadth (aka scope) dictates the master data domains and major business entities/data elements that would be addressed as part of the master data management program. The depth portion focuses on the enterprise reach Vs departmental reach.
As we get closer and closer to the enterprise level use of single source of master data repository and have all the intended (in-scope) data in the master data store/s, we get better and better scores for this measure.
2) Data Services:
Now we have the data in scope defined for the master data stores and measured it for the content, we need to switch our attention to the accessibility of it to consuming applications across the enterprise.
‘Data Services’ portion measures the ability of the organization to access and manage master data information in the master data stores quickly, easily and securely for consuming applications. This is a fundamental step towards reducing the time to market and project turnarounds. Currently many of the IT projects for business purposes spend a good deal of their time and money in gathering basic information, integrating , cross checking, quality checking etc. as part of these business projects. By adopting this measure, we are ensuring that the focus is centered in moving this fundamental efforts to one time centralised placed so that future business projects are freed from this step.
The basic assumption here is to have a layer of data services around the master data stores so that nobody need to directly use the master data store tables. Both custom build and software product use situations, data structures used for master data is quite complex and abstract than usual data structures. So this is a very important often ignored capability in the master data management domain.
This can be further subdivided into multiple type of data services. Of course the most important is the base services in which basic CRUD and simple search services are exposed. Initial days only the basic CRUD and/or logical grouping of them was considered as data services. However, Advanced searches like probabilistic searches and lifecycle management services also considered as data services now and are good line items for measurement under the data services umbrella.
In the early days of master data management (let us say 2005 ish) nobody considered services beyond these relatively simplistic data services. However, due to the introduction of vendor products and the ‘need to show immediate results’ vendors tried to put more into their products. A good example is lifecycle management services. This create a whole ‘platform of MDM’ which is expected to readymade. Needless to say this is not an invention. Earlier days this is considered to be a custom made business process for each organiziation and probably for each line of business and probably even specific to product categories. Because the lifecycles and rules associated to that are so integrated and specific. Now a days many consider or at least expect this lifecycle services as a outcome of master data management. Right or wrong.
Having these expectations also in mind, here is a high level list of categorization of data services for measurement purposes is given here.
a) Key generation Services
b) Base Data Services
c) Lifecycle Data Services
d) History data services
e) Simple Search services
f) Probabilistic search services
However most of the MDM implementations nowadays are using software products and almost all of them provide a good set of data services in various names. However the robustness and usability of these varies and so we still need this measure, even when we use vendor products.
3) Universal IDs (Single IDs)
A generally accepted objective and probably the hardest of all the objectives is to attain is a single universal id for a piece of information. Or say single version of truth. Like Customer ID or Product ID or a Store ID. The idea is that any system across the organization can then use this id and access the same exact information.
Needless to say that currently all major organizations have multiple systems with its own replicated data and have different Identifiers for same data in each system. In the past, we kept creating copies, in the name of ease of access, business intelligence projects etc. Almost anytime we integrated data from multiple systems, we said that the new id is “the ID’. And of course that lived only till the next system integration project and newer ID. Many of these projects kept consolidating all the information from these disparate systems and brought all these identifiers and associated information to a single system. Now, that would help them on the first measure of ours, the “Data Content”. However, single ID, not yet. Only thing that happened now is, say six records from six systems is moved to a single data store but as six separate instances(aka records). So which one of the six instances is the right one? Well, no answer. There were efforts to consolidate attribute by attribute to a single record. Well, that requires manual intervention and takes years for all the millions of records. But there aren’t many short cut anyway. There are lot of data quality/matching software promised the magic of consolidation, but practically any organization is far away from this ideal state of reaching that single record.
So this measure focuses on the maturity of the data in this area. And this is key measure in the MDM maturity and differentiating an MDM project from becoming yet another data integration project (another copy of that data again).
4) Data Quality
First of all, this book is not about data quality. It is only about adopting master data management. So anything that is needed for that adoption and the completeness of that is discussed here. Data Quality is understandably a imperative part of MDM. But organizations vary widely in their definition of data quality. The terms data quality and data governance are so overlapped and so it is confusing. Since MDM programs are specific point of action, these points converge and confuse the MDM domain also. So the objective here in this book is to forget the very broad definitions of data quality (and data governance) and adopt a measure that focuses only on master data and only for data quality issues and processes that is relevant and necessary for a complete and mature master data. This may not be suitable for an enterprise wise ‘data quality’ program. However, this is a very good point to start the action of data quality and then generalise it and grow it into the enterprise programs.
Data Quality is one of the most used, abused and marketed term in the MDM industry. But on the good side, MDM is bringing lot of attention to data quality and there are serious thought and efforts happening in the data quality side. And the association of data quality to master data management enhance each other. This is because the focus on ‘master data’ give data quality a razor sharp focus in one of the most impactful areas but not necessarily immediately impactful. It also bring certain repeatable processes across industry. So it becomes much more practical to do in the real life situation in many organizations. Because now you can start small, focus and arguably easy to demonstrate success, then scale up and make it sustainable than it used to be in a general case.
On the negative side, Data Quality is another beat up term in the industry overall. It is often associated with large enterprise programs, buying new software, lot of presentations, data quality stewards, their role definitions, business case building to get financing for all these etc..
Also in a different view, the data quality effort’s success can be questioned in a different way. Because it may not be immediately visible or useful. For example, A need some good quality customer data for some campaign mailing. This data has to be based on the campaign management system. And we did the data quality improvements in the master data system. If the campaign management is not integrated with master data system that improvements are not really available to the campaign program easily. So even though there are some lot term prospects for improving the campaign using better data quality, it is not available immediately.
Majority of the organizations, data quality programs are associated to specific IT systems. Like a specific data warehouse, or a business units like campaign management etc.. Of course there are organizations of exception in with there are disciplined data quality programs covering the whole organization data and processes. But let us not focus on them as their numbers are very limited.
Overall, MDM gives a good opportunity to start a data quality program in very focused way. We can focus on specific data quality issues in the domain as well as built out a repeatable data quality program as part of MDM. And we can measure the quality of data in quantitative terms.
The important thing is not to get caught up in the never ending theory discussion cycles and business case cycles but to get it started. And not to get hung up on what is contained in what, like MDM as part of data quality effort or data quality as part of MDM.
5) Data governance
This measure focuses of the data governance aspects needed for master data management and the maturity of it. Not necessarily the maturity of the data governance program in the organization overall. Ie; we donot really focus on the maturity or reach of data governance program in the transactional or analytical data domains. However, this ensures that all the elements of data governance is in place for the successful implementation and maturing of the master data management of the organization.
MDM can be done without Data Governance or Data Quality for sure. But the value would be very diminished. It would look like just another ETL project, just like in the BI space, but for master data. However, it is a good first start, if done with as part of a well planned out roadmap. To some extend data governance is imperative is some form even for the implementation of an initial phases of the program. But it surely need not be under the “brand name” of data governance. We need to focus on why we need data governance. What are the vehicles for such things in the organization. We would find gaps. Then either need to fill the gaps or convert these tasks and processes under the umbrella of data governance and add the missing elements. We would focus on such a process just for the master data management program.
6) Mastering of Data
Immediately after you have that single record with single ID, you are immediately followed by the problem of keeping it that way!
The question is, are you creating and managing the data in the master data store as per your end state? May be you have achieved all the above measures. Eg: you are bringing data from five systems, using a complex logic to merge it and create that single record, use a work queue system to manage the output of the matching engines etc.. And data is constantly being fed from the sources to this master store. You achieved a good score in all other measure. But what about stop creating the master data in five places to begin with and create it directly in the master store for the master data? You can get rid of these backend processes, matching all these if you are able to do that. This is kind of optimization and continuous improvement area. You would need strong data governance systems in place to enable the organization change that comes with this. So this measure tracks that amount of data being mastered in the master data store as opposed to being the slave of other data stores.
There is a large cost associated to re-engineering these processes and systems making any attempts to change this difficult. However, there is enough value in altering these and moving the creation of specific data (as specified in the scope of each master data store) into the master data stores. During the initial creation of these data stores the mastering is not always in the master data stores. However, this usually causes a delay in having the master data in central datastore and it being available to rest of the telus. This delay in not very important for reporting and business intelligence purposes but very important in operational functions like customer self serve, call center supports functions etc.. One day of delay in reaching the information from one system is very inefficient here.
This measure is analyzing the maturity in this domain. Of course this need to be measured for each business entity. A low score for the measure will mean that a data expected to be mastered in the master data source is reaching there in a very offline way (Say a week) to the best possible situation that this data is created in the end state location and is fed to every consumer of this information real time.
MDM Maturity Model

First of all, a big thanks to DALIA HUSSEIN for spending a lot of time encouraging me and reviewing most of the content here and enriching it with great feedback.
ReplyDeleteHi there! glad to drop by your page and found these very interesting and informative stuff. Thanks for sharing, keep it up!
ReplyDelete- master data management